RAID1コントローラーには、HDDのMBRよりも先頭にRAIDシステムの管理データを書き込むものがあります。メジャーな製品では3ware社のEscaladeシリーズなんかがそうです。 このようなRAID1コントローラーでビルドしたハードディスクを使っていて、下記のようなトラブルに遭遇したら本ページの手法でデータサルベージができるかも知れません。
このページが対象とするのは、MBRよりも先頭にRAIDシステムの管理データを書き込むタイプのRAID1ディスクで、なおかつ後述の原因によりデータが読めないケースです。
RAID0やRAID5のトラブルは本ページの対象外です。
ハードディスクが物理的に損傷している場合は、このページの手法を取る前にハードディスクのイメージの保全を先に行ってください。イメージの保全方法についてはこのページでは述べませんが、重要なデータがあるハードディスクが物理的に損傷した場合は、信頼できるデータサルベージ業者のご利用を強くおすすめします。
Debian Lenny では、パッケージ"multipath-tools"をインストールしないとkpartxが使えません
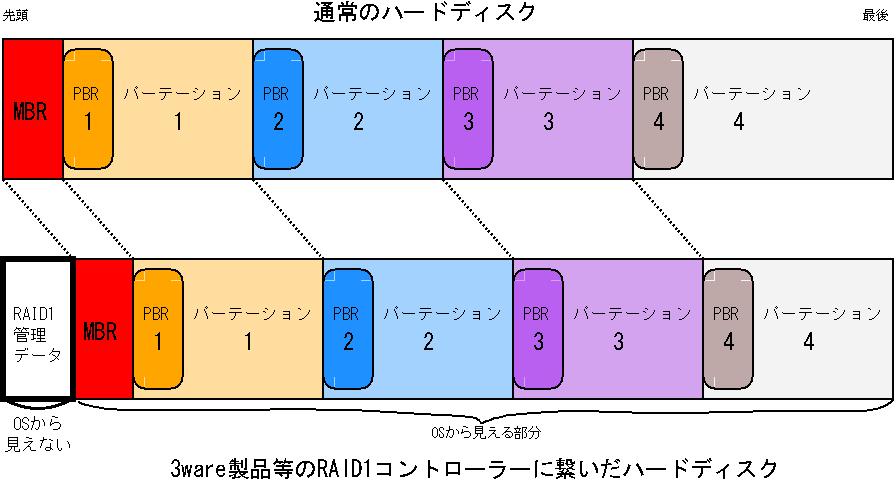
(MBRで管理される)通常のハードディスクについて
ハードディスクは1~4つの基本パーテーションに区切られています。そしてそれぞれの基本パーテーションがハードディスクのどこに位置するのかという情報はMBR領域に書き込まれています。
OSがハードディスクをマウントするときは、このMBR領域を参照します。MBRは本来ハードディスクの最も先頭にあります。
ハードウエアRAID1コントローラーに繋がれているハードディスクについて
RAID1システムには、2台のハードディスクを1台のディスクとして管理するためのデータが必要で、これをどこかに記録しなくてはなりません。
ハードウエアRAID1コントローラーは、一般にハードディスクの先頭か最後の部分にこの管理データを置いて、ハードディスクから管理データを除いた部分をOS
に提供しています。上図下段は、先頭にRAID1システムの管理データを書くタイプのコントローラーに繋がれたハードディスクのパーテーションを示しています。OSにはRAID1管理データが隠蔽されるので、OSは本来のハードディスクよりも管理データ分だけ容量が小さなハードディスクとしてこのディスクを扱います。
MBRはハードディスクの本当の先頭より後ろに存在することになりますが、RAID1コントローラーに繋いでいるならばOSにはRAID1管理データ部分が見えないので、これで問題ありません。
ハードウエアRAID1コントローラーに繋いでいたディスクが読めない理由
上図のように先頭にRAID1コントローラーの管理データが書かれたハードディスクを、通常のハードディスクコントローラーに繋ぐと、OSはハードディスクの本当の先頭からパーテーション情報を読もうとしますが、そこにはMBRが書かれてないのでOSはこのハードディスクを扱うことができないのです。本ページが対象とするのはこの理由により読めないディスクのみです。
ハードウエアRAID1コントローラーに繋いでいたディスクが通常のコントローラーで読めない理由は、上記以外にも考えられます。その場合には本ページの手法は全く適用できません。以下の作業は、上記理由によりディスクが読めないということに責任が持てる場合にのみ行ってください。
作業の方針
MBRの位置を調べてから、RAID1管理データ部分を除外したハードディスクのイメージをループバックデバイスに割り当て、このループバックデバイスを通してデータのサルベージを行います。ループバックデバイスに含まれる各パーテーションをマウントするためには、パーテーション毎のPBRを計算して
mount コマンドのオプションとして渡す方法もあるのですが、面倒くさいのでそれよりずっと簡単な kpartx という Linux のコマンドを使うこととします。
kpartxはハードディスクのイメージを指定してやると、ディスクに含まれるパーテーションそれぞれに対して自動的にデバイスファイルを割り当ててくれる(マッピングしてくれる)というコマンドです。kpartxによってマッピングされたデバイスファイルは実際のHDD上のパーテーションとして扱うことが可能です。
MBRが壊れたときに、パーテーションの境界を自動的に見つけ出してハードディスクを復旧する "TestDisk"という優れたツールがありますが、2010年6月時点のバージョンではRAID1で使っていたハードディスクを通常のコントローラーに繋いだ場合の復旧には使えないようです。
MBR開始位置の推定 -RAID1コントローラー使用時のMBRを探します
RAID1コントローラーにつながっていたHDDを通常の(ATA/SATA/SCSI)コントローラーに接続し、それと別のドライブからLinuxを起動します。
次にRAID1コントローラーにつながっていたHDDのMBRが含まれていそうな部分をファイルに落とします。
RAID1コントローラーにつながっていたHDDが、/dev/sdzにあり、MBRはその先頭の10000セクタ以内にあると予想したなら
dd if=/dev/sdz of=sdz.bin count=10000
というコマンドでHDDの頭のほうを sdz.bin というファイルに落とします。 次に sdz.bin をお好きなバイナリエディタ/バイナリビューアーで開き、MBRに特徴的な文字列を検索します。
Windowsだけをインストールしていたドライブなら、"Invalid partition table"という文字で検索をすれば良いでしょう。
表 ドライブのブートローダーと、MBR領域に含まれる文字列
| ブートローダー | 含まれる文字列の例 |
|---|---|
| Windows標準 (ntldr) |
"Invalid partition table","Error loading operating system" |
| grub,grub2 | "GRUB","Geom","Hard Disk","Error" |
| syslinux | "Missing operating system","Multiple active partitions" |
検索で文字列が引っかかったら、MBRの開始位置を推定します。
MBRの開始位置は、検索文字列からHDD先頭に向かって512バイト以内にあるはずです。
MBRの開始位置はたぶん16進数でキリのいい場所にあります。
MBRの開始位置より先頭方向には&H00が連続してるケースが多いでしょう。
私が使っている3WareのRAID1コントローラーの場合、MBR開始位置は先頭から&H80000バイト目(&H80000バイト
= 524288バイト = 1024セクタ * 512)でした。
Promise社のRAID1コントローラーには、2つあるハードディスクのうち片方にしか正しいMBRを書かない製品もあるそうですのでご留意ください。
MBR開始位置の確認
losetup -f
により、使われてないループバックデバイスの番号を調べます。次いでそのループバックデバイスにHDDをMBRの先頭位置のずれを除外して割り当てます。
具体的には、losetup -f の結果が loop0であり、MBR推定位置が先頭から524288バイト目だったら、
losetup -o 524288 /dev/loop0 /dev/sdz
というコマンドになります。
コマンドが通ったら、
fdisk -l /dev/loop0
というコマンドを打ってみてください。もしMBR推定位置が正しければ、RAIDコントローラーに繋いでいたときと同じハードディスク情報が表示されます。
ここまでできればデータ復旧はまず問題いなし。やったね!
マウント
losetup -f の結果が loop0 であるなら、
kpartx -a /dev/loop0
とコマンドを打ちます。これでRAIDコントローラーに繋いでいたHDDの各パーテーションが /dev/mapper 以下にマッピングされます。
ls /dev/mapper
とすれば、/dev/mapper 以下に /dev/mapper/loop0p1 等のデバイスが、パーテーションの数だけできていると思います。
これらのデバイスはふつうに mount コマンドでマウントすることができます。
もし、HDDの第一ドライブがNTFSフォーマットなら
mount -t ntfs /dev/mapper/loop0p1 /mnt/mountpoint
などというコマンドでマウントして、読めるようになります。 ( ntfs-3g オプションが使えるなら書き込みも可能)
誤って通常のHDDコントローラーからMBRを書き込んでしまったディスクでも、MBR以外に書き込みがされてないなら、マウントができてデータを完全にサルベージできるでしょう。
なお、読めるようになったディスクをddコマンドなどで別ドライブにパーテーションごとコピーしてそのまま運用するのは不良セクタやアライメントの問題から避けるべきだと思います。
作業の終了
作業が終わったら、逆の順番でデバイスを解放していきます。
上記の場合だと、次のようなコマンドになります。
umount /mnt/mountpoint
kpartx -d /dev/loop0
losetup -d /dev/loop0
このページで紹介した以外に、「ハードディスクのイメージから RAID1の管理データ分だけを除いて別の容量が多いハードディスクにコピーする」ことでオリジナルディスクを復旧する手段もあります。
具体的には、ハードディスクの1セクタが512バイトであり、上述したMBRの先頭位置のずれが XX セクタであるなら、
dd if=/dev/(raid1で使っていたドライブ) of=/dev/(コピー先ドライブ) bs=512 skip=XX
という風なコマンドを使う方法です。
ただ、この手法はコピー先に不良セクタがある場合に、わずかでありますが不具合が出ることがあります。また、復旧したドライブをそのまま使う場合は、ディスクアライメントの問題によりドライブの性能が十分に出ないかも知れません。
2010/7/1更新
文書作成者のメールアドレス: infoアットマークmail.a2the.net